 Mes conférences en vidéo
Mes conférences en vidéo30 Avr 2016
Récupérer les textes, les polices et les images d’un document pdf
Vous avez téléchargé un document pdf et vous souhaitez récupérer les images, les polices de caractères et les textes qui s’y trouvent ?
Voici deux moyens gratuits pour y arriver rapidement :
- une version en ligne qui se prénomme tout simplement Free online PDF Extractor,
- une version à télécharger, Nitro Reader, qui est également un visualisateur.
La version en ligne est limitée à des fichiers de 14 Mo. Une fois le téléchargement du document réalisé, vous avez un onglet qui affiche les images extraites, un autre le texte et un troisième les polices de caractères. Pour chaque onglet, vous pouvez télécharger tous les éléments, mis dans un zip, d’un simple clic. Les images sont dédoublonnées. Il se peut que certaines d’entre elles ne soit pas bien récupérées lorsqu’elles ont de la transparence.
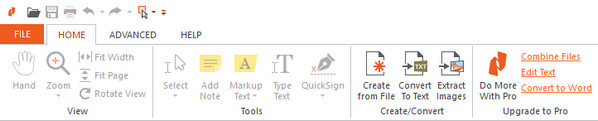
La version à télécharger est avant tout un visualisateur de documents pdf. Pour extraire les images, il suffit d’appuyer sur le bouton « Extract images ». Les images extraites n’ont pas les mêmes problèmes que la version en ligne, mais elles ne sont pas dédoublonnées. Celles qui apparaissent sur plusieurs pages sont répétées pour chaque page. L’extraction de texte se fait avec le bouton « Convert to text ». Il n’y a pas de possibilité d’extraire les polices de caractères. La version payante vous permet de regrouper plusieurs documents pdf en un seul, fait de la reconnaissance de caractères à partir d’un document scanné et convertit un document pdf en document Office, ce qui est intéressant si l’on veut garder la mise en page. Mais à 180 Euros, cela fait cher.
 Mots clés :
Mots clés : 
Ajoutez un commentaire